
About Me
I am a Principal AI researcher at DataRobot. Prior to that I was a staff scientist at Latitude AI focusing on improving autonomy for self-driving vehicles. Before that I was a researcher at Microsoft Research in Redmond, WA. I previously obtained a PhD in Computer Science from the University of Texas at Austin advised by Professor Peter Stone.
I work at the intersection of deep learning and reinforcement learning to develop autonomy capable of adapting and learning in complex environments.
Publications
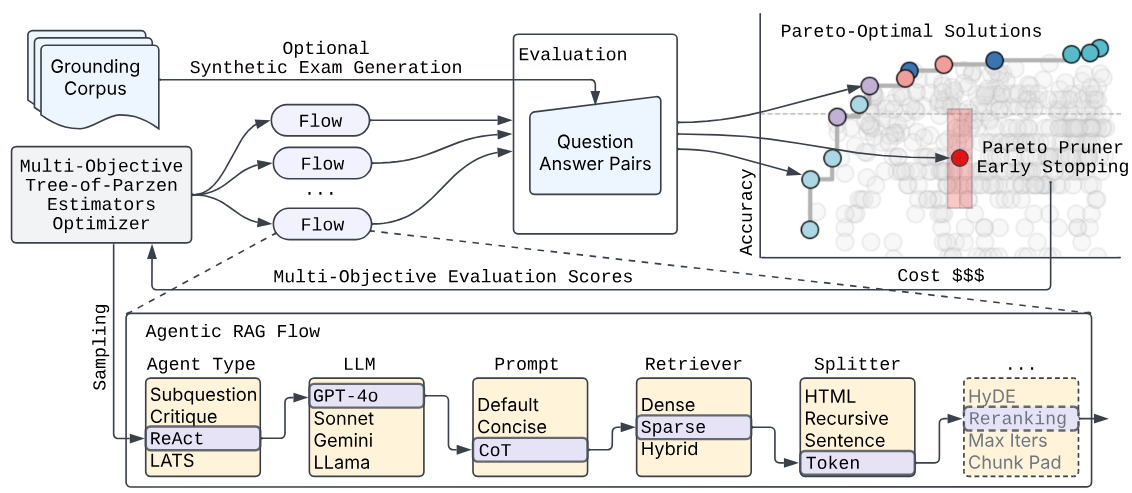 |
syftr: Pareto-Optimal Generative AI A Conway, D Dey, S Hackmann, M Hausknecht, M Schmidt, M Steadman, N Volynets. 2025 International Conference on Automated Machine Learning (AutoML Oral) |
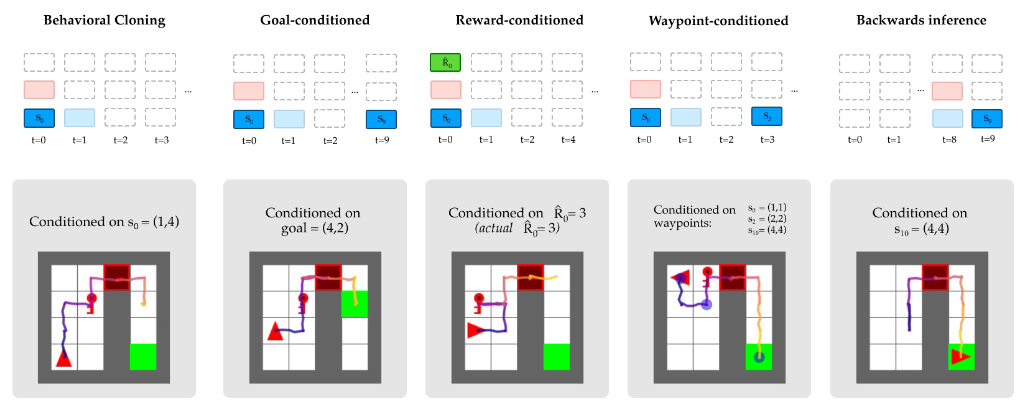 |
Uni[Mask]: Unified Inference in Sequential Decision Problems M Carroll, O Paradise, J Lin, R Georgescu, M Sun, D Bignell, S Milani, K Hofmann, M Hausknecht, A Dragan, S Devlin. 2022 Conference on Neural Information Processing Systems (NeurIPS Oral) |
 |
MoCapAct: A Multi-Task Dataset for Simulated Humanoid Control N Wagener, A Kolobov, F Frujeri, R Loynd, C Cheng, M Hausknecht. 2022 Conference on Neural Information Processing Systems: Datasets and Benchmarks Track (NeurIPS) [Webpage] [Blog Post] [Code] |
 |
Consistent Dropout for Policy Gradient Reinforcement Learning M Hausknecht, N Wagener. 2022 arXiv Preprint |
 |
Reading and Acting while Blindfolded: The Need for Semantics in Text Game Agents S Yao, K Narasimhan, M Hausknecht. 2021 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) [BlogPost] |
 |
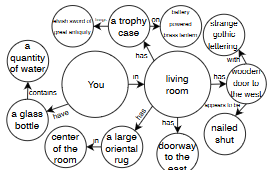
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning M Shridhar, X Yuan, M Côté, Y Bisk, A Trischler, M Hausknecht. International Conference on Learning Representations (ICLR) 2021 [Webpage] |
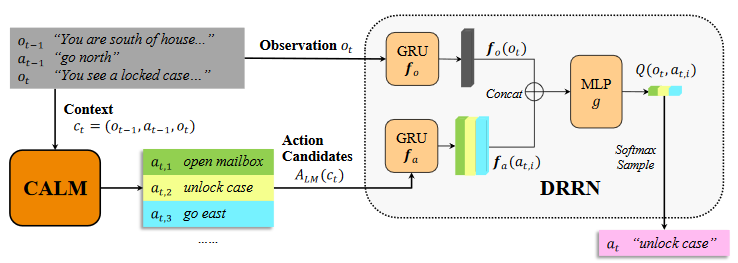 |
Keep CALM and Explore: Language Models for Action Generation in Text-based Games S Yao, R Rao, M Hausknecht, K Narasimhan. Empirical Methods in Natural Language Processing (EMNLP) 2020 [Code][Video] |
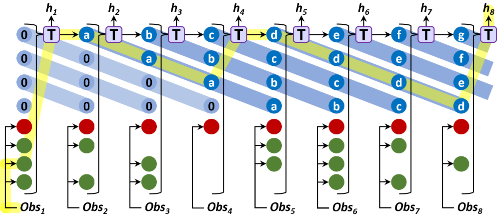 |
Working Memory Graphs R Loynd, R Fernandez, A Celikyilmaz, A Swaminathan, M Hausknecht. International Conference on Machine Learning (ICML) 2020 [Code][Video] |
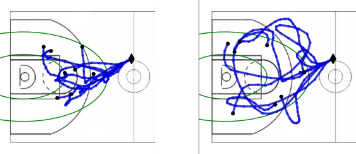 |
Learning Calibratable Policies using Programmatic Style-Consistency E Zhan, A Tseng, Y Yue, A Swaminathan, M Hausknecht. International Conference on Machine Learning (ICML) 2020 |
 |
Graph Constrained Reinforcement Learning for Natural Language Action Spaces P Ammanabrolu, M Hausknecht. International Conference on Learning Representations (ICLR) 2020 [Code] |
 |
Interactive Fiction Games: A Colossal Adventure M Hausknecht, P Ammanabrolu, M Côté, X Yuan. Association for the Advancement of Artificial Intelligence (AAAI) 2020 [Code][Blog Post] |
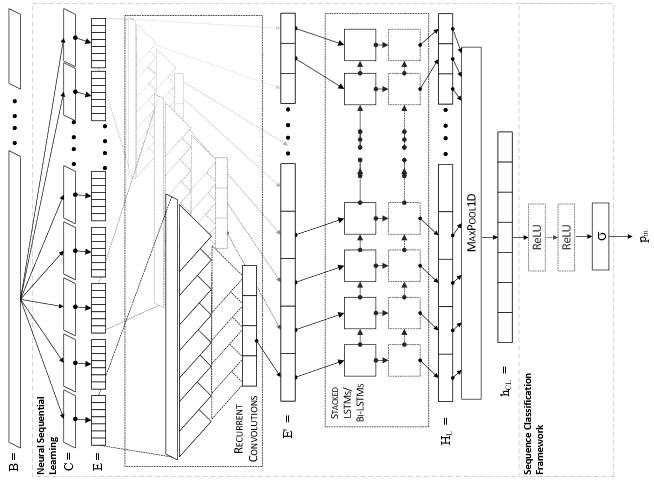 |
Scriptnet: Neural static analysis for malicious javascript detection J Stokes, R Agrawal, G McDonald, M Hausknecht.IEEE Military Communications Conference (MILCOM) 2019 |
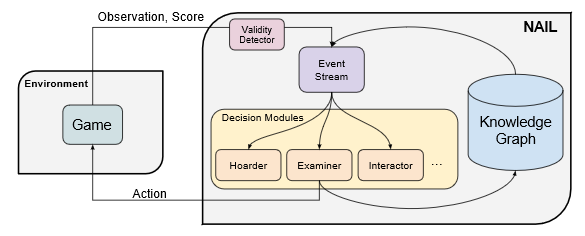 |
Nail: A general interactive fiction agent M Hausknecht, R Loynd, G Yang, A Swaminathan, JD Williams.Technical Report 2019 [Code] |
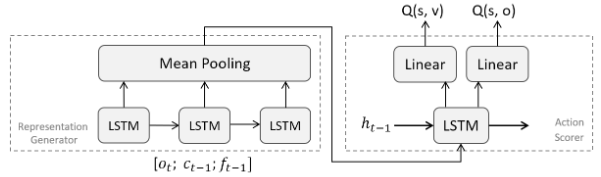 |
Counting to Explore and Generalize in Text-based Games X Yuan, M Côté, A Sordoni, R Laroche, R Tachet des Combes, M Hausknecht, A Trischler. European Workshop on Reinforcement Learning (EWRL) 2018 |
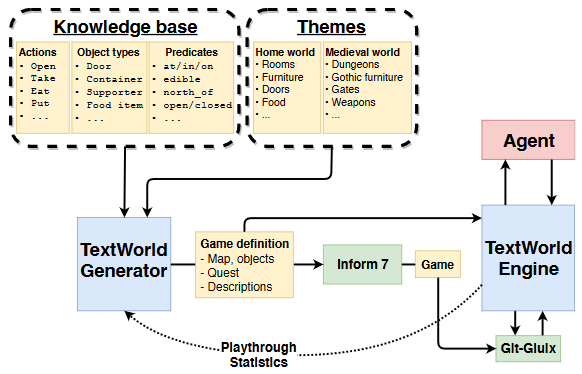 |
TextWorld: A Learning Environment for Text-based Games M Côté, A Kadar, X Yuan, B Kybartas, T Barnes, E Fine, J Moore, M Hausknecht, L Asri, M Adada, W Tay, A Trischler. IJCAI/ICML Computer Games Workshop 2018 [Code] |
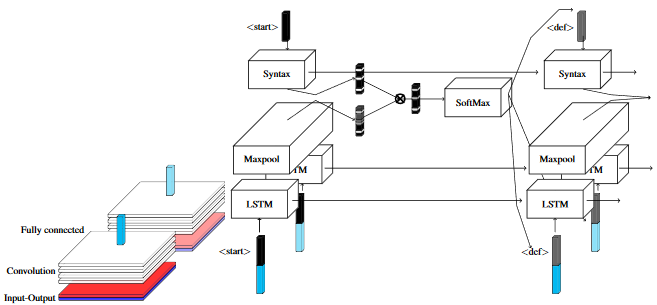 |
Leveraging grammar and reinforcement learning for neural program synthesis R Bunel, M Hausknecht, J Devlin, R Singh, P Kohli. International Conference on Learning Representations (ICLR) 2018 |
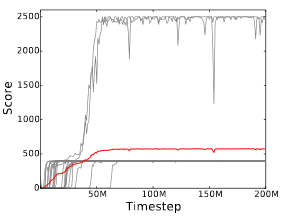 |
Revisiting the arcade learning environment: Evaluation protocols and open problems for general agents MC Machado, MG Bellemare, E Talvitie, J Veness, M Hausknecht, M Bowling. International Joint Conferences on Artificial Intelligence (IJCAI) 2017 |
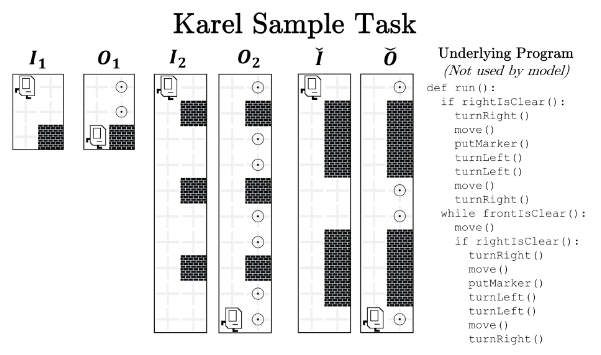 |
Neural Program Meta-Induction J Devlin, RR Bunel, R Singh, M Hausknecht, P Kohli.Advances in Neural Information Processing Systems (NeurIPS) 2017 |
 |
Cooperation and communication in multiagent deep reinforcement learning Matthew Hausknecht. PhD Thesis 2016 |
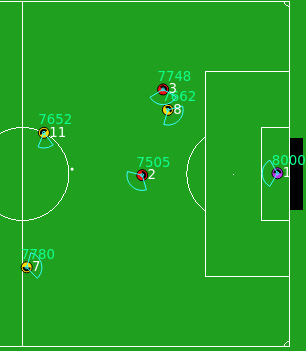 |
Half field offense: An environment for multiagent learning and ad hoc teamwork M Hausknecht, P Mupparaju, S Subramanian, S Kalyanakrishnan, P Stone. AAMAS Adaptive Learning Agents (ALA) Workshop 2016 |
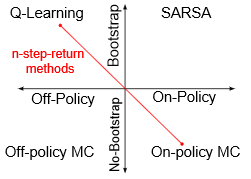 |
On-policy vs. off-policy updates for deep reinforcement learning M Hausknecht, P Stone.Deep Reinforcement Learning: Frontiers and Challenges, (IJCAI) Workshop 2016 |
 |
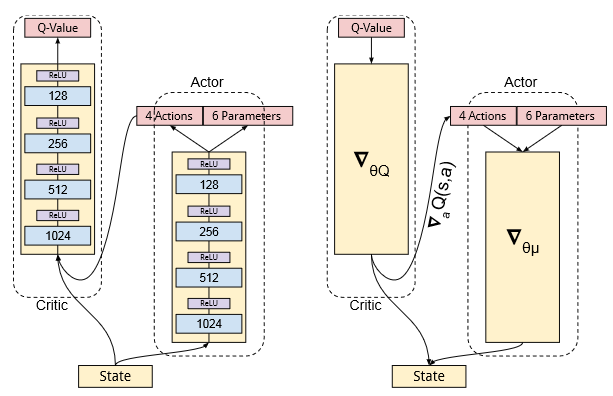
Deep Reinforcement Learning in Parameterized Action Space M Hausknecht, P Stone. Proceedings of the International Conference on Learning Representations (ICLR) 2016 [Code] |
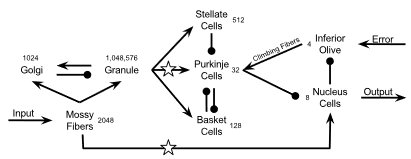 |
Machine Learning Capabilities of a Simulated Cerebellum M Hausknecht, W Li, M Mauk, and P Stone. IEEE Transactions on Neural Networks and Learning Systems (TNNLS) 2016 |
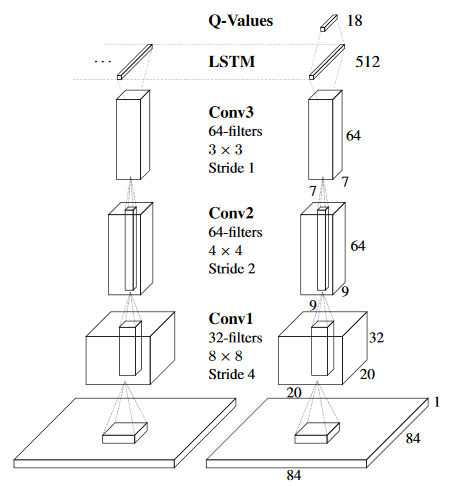 |
Deep Recurrent Q-Learning for Partially Observable MDPs M Hausknecht, P Stone. AAAI Fall Symposium on Sequential Decision Making for Intelligent Agents 2015 |
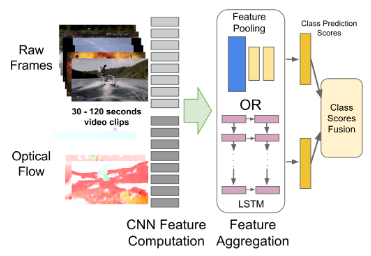 |
Beyond Short Snippets: Deep Networks for Video Classification J Ng, M Hausknecht, S Vijayanarasimhan, O Vinyals, R Monga, G Toderici. Conference on Computer Vision and Pattern Recognition (CVPR) 2015 |
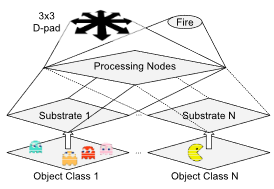 |
A Neuroevolution Approach to General Atari Game Playing M Hausknecht, J Lehman, R Miikkulainen, and P Stone. IEEE Transactions on Computational Intelligence and AI in Games (TCIAIG) 2014 |
 |
Using a million cell simulation of the cerebellum: Network scaling and task generality W Li, M Hausknecht, P Stone, and M Mauk. Neural Networks 2012 |
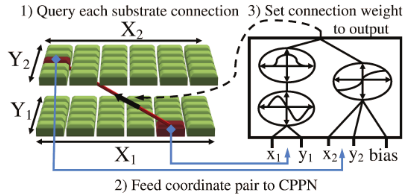 |
HyperNEAT-GGP: A HyperNEAT-based Atari General Game Player M Hausknecht, P Khandelwal, R Miikkulainen, and P Stone. Proceedings of Genetic and Evolutionary Computation Conference (GECCO) 2012 |
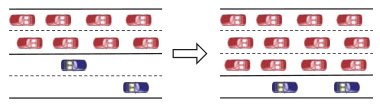 |
Dynamic Lane Reversal in Traffic Management M Hausknecht, T Au, P Stone, D Fajardo, and T Waller. Proceedings of IEEE Intelligent Transportation Systems Conference (ITSC) 2011 |
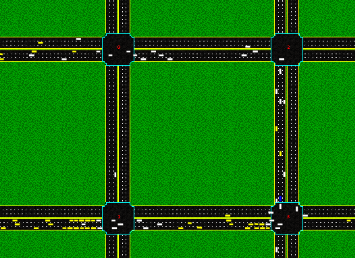 |
Autonomous Intersection Management: Multi-Intersection Optimization M Hausknecht, T Au, and P Stone. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2011 |
 |
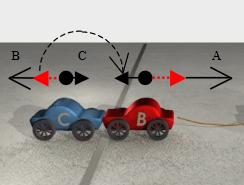
Learning Powerful Kicks on the Aibo ERS-7: The Quest for a Striker M Hausknecht, P Stone. Proceedings of the RoboCup International Symposium 2010 |
 |
For want of a nail: How absences cause events P Wolff, A Barbey, M Hausknecht. Journal of Experimental Psychology: General 2009 |
Open Source Software
I’ve built or contributed significantly to the following open-source projects:
 |
Jericho is a lightweight python-based interface connecting learning agents with interactive fiction games. It serves as a testbed for benchmarking progress of language-based agents on man-made text games. BlogPost |
|
Half Field Offense (HFO) is a multiagent subtask in RoboCup simulated soccer, modeling a situation in which the offense of one team has to get past the defense of the opposition in order to shoot goals. |
 |
Arcade Learning Environment (ALE) Is a well known platform for training learning agents to play Atari games. I developed the first external interface to ALE which allowed the environment to be used as a library. |